
Understanding Chi Square
How do you calculate?

1 — Get sum of Male and Female with the Survived and not Survived Categories
expected frequency is sum of male and Female

2 — Calculate the frequencies by observations / total in each column

3- In the Green is the expected Frequency and we can clearly see that the Female and Male Real Frequencies don’t match that.
Hence the Hypothesis that Male and Female had equal survival rates is false

4- Sum of eg (0.19 -0.38) squared / 0.38 + (0.81 -0.62) squared / 0.62……….. n numbers

5 — Once you have this you can put it in a distribution and compare it with a known distribution of chi square
Best Used for - Categorical which are Boolean,Frequency and Counts that are non negative
Scikit Learn— Implementation of Chi2
Process is 2 Steps
1- Implement Chi2 / Anova to rank the features
2 - Use SelectKBest for K Best Or SelectPercentile to select the top Percentile of Features
Step1 — Get the Ranking of the Features
from sklearn.feature_selection import chi2
from sklearn.feature_selection import SelectKBest

1- Import Titanic

2- Use Label Encoder to map the categorical features to numerics
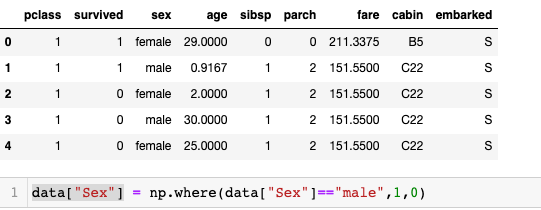
3. Train Test Split the data

4 — Implement chi2 and get the F scores
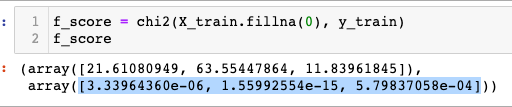
IMP the first array is the F_score , 2nd one is the P_values ( you want to analyze this) the smaller the P value the more significant the difference in the features
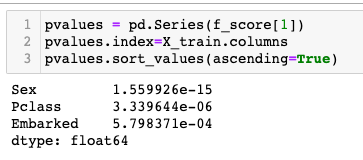

We know from this the Feature — Sex with lowest P Value was most significant in the outcome of Survival
Step2 — Get the Top Selected Features
SelectKBest
sel_= SelectKBest(chi2,k=1).fit(X_train,y_train)
now we use the SelectKBest Model with the chi2 classifier to find the best features , output is Feature “Sex”

sel_.get_support()
gets you the name of the columns
Lastly transform back to the dataframe to remove the other columns

Anova
Recommended Reading
ANOVA assumes a linear relationship between the feature and the target and that the variables follow a Gaussian distribution. If this is not true, the result of this test may not be useful.
Univariate does not show the relationship between two variable but shows only the characteristics of a single variable at a time.
In contrast, ANOVA can tell if an independent variable (e.g. categorical) has significant influence on Dependent variable (ordinal).
Must meet these conditions
2 or more samples have the same mean
Samples are independent of each other
Samples are normally distributed
Homogeneity of variance
Calculation intuition
1-Divide Feature with Target 1 and 0 — Obs 0 , Obs1
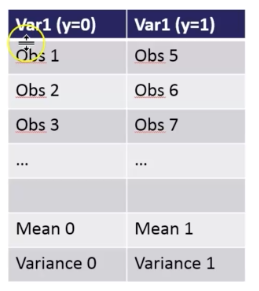
2- Calculate the mean of Var1 and Var2
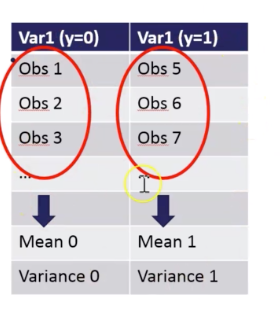
3- Calculate Great Mean by sum of all observations/ number of observations
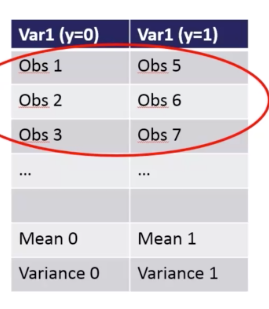
4- we calculate these two with the above information

5- Finally F-Statistics is calculated

What about Regression values and not Categorical?
We use correlation and convert it to pvalues

Step1 — Get the Ranking of the Features
1- Categorical — Use the f_classif method

2 — The 2nd values are the PValue and we capture those below

3. The higher the P Value the lesser the importance of this feature
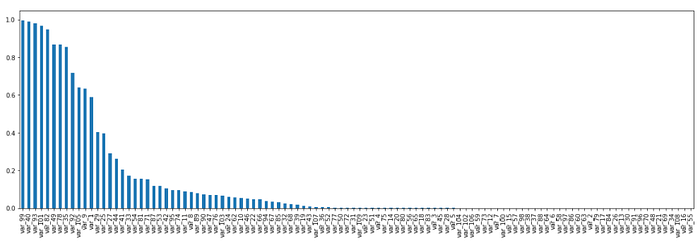
Step2 — Get the Top Selected Features
Implement SelectKBest with f_classif

Anova for Regression Problems
Same implementation but we use f_regression

Instead of SelectKBest we use SelectPercentile with f_regression and all features in the 10 percentile range

